The AI world is obsessed with leaderboards. But for builders and “vibe coders,” MMLU scores mean nothing compared to how a model actually feels on a mid-range laptop or a Mac.
I decided to ignore the benchmarks and focus on output. After a week of aggressive testing, the conclusion is simple: If I could only use one LLM for web design and programming, it would be Gemma 4.
The Hardware Reality Check
Most recommendations assume you have a cluster of H100s. My reality is a 2021 Zephyrus G15 (32GB RAM / 8GB VRAM). After switching to Ollama, I put the Gemma 4 26B variant through its paces.
Although gemma4:26b didn’t fit into the VRAM, it run OK. This is a game-changer, allowing me to run ComfyUI, Forge WebUI, and Qwen3TTS in addition to Gemma 4 powering the Hermes Agent on my LAN.
The “Aha!” Moment: Web Design
The real surprise came on my Mac Studio M4 Max (36GB memory) using the heavy hitter: gemma4:31b.
I asked it to do something useful: develop a web page. If you visit the index page of BeginnerProjects.com, you are seeing the direct result. The code was clean, aesthetically sound, and logically structured. Every request for a layout shift or CSS improvement was executed without hallucination. For the first time, the AI seemed to actually understand the design intent.
The Daily Driver: Programming & Workflow
I evaluate models on one strict metric: How much of the work does it actually finish? Over the last few days, gemma4:31b has been my primary driver 90% of the time.
Integrating it with the Continue extension in VSCodium has been seamless. The latency is low, the context window is handled elegantly, and the code is production-ready. While I use the Hermes Agent for automation, for the act of creation—coding, designing, and writing—Gemma 4 is in a league of its own.
New Test with Stats
The Ollama prompt used:
Write a complete, single-file HTML and Tailwind CSS landing page for a fictional AI-powered gardening app called ‘GreenThumb’. Include a hero section, a features grid with 3 items, a pricing table, and a contact form. Ensure the code is clean and production-ready.
Real Unmodified Results
Zephyrus G15 2021 model
- gemma4:26b
- total duration: 6m10.491446169s
- load duration: 182.365261ms
- prompt eval count: 72 token(s)
- prompt eval duration: 1.225581594s
- prompt eval rate: 58.75 tokens/s
- eval count: 5489 token(s)
- eval duration: 6m4.610814349s
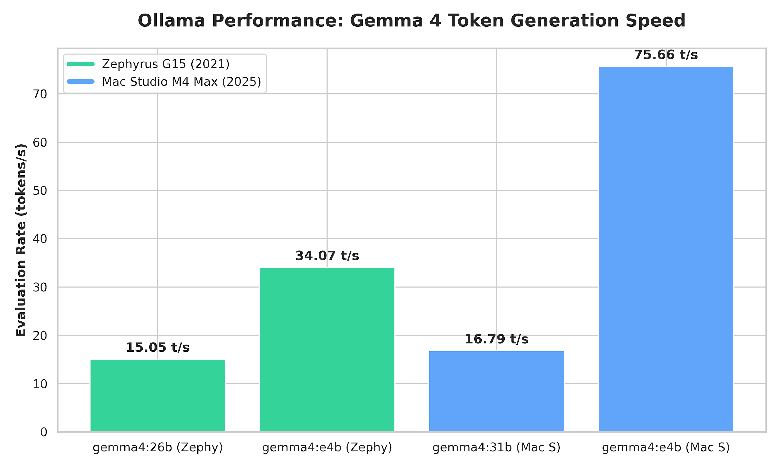
- eval rate: 15.05 tokens/s
- gemma4:e4b
- total duration: 2m42.753148258s
- load duration: 188.386751ms
- prompt eval count: 72 token(s)
- prompt eval duration: 123.856248ms
- prompt eval rate: 581.32 tokens/s
- eval count: 5453 token(s)
- eval duration: 2m40.03374239s
- eval rate: 34.07 tokens/s
Mac Studio M4 Max 2025 model
- gemma4:31b
- total duration: 5m8.619550833s
- load duration: 131.937666ms
- prompt eval count: 73 token(s)
- prompt eval duration: 604.740125ms
- prompt eval rate: 120.71 tokens/s
- eval count: 5209 token(s)
- eval duration: 5m6.684044325s
- eval rate: 16.79 tokens/s
- gemma4:e4b
- total duration: 1m21.762662375s
- load duration: 133.09975ms
- prompt eval count: 133 token(s)
- prompt eval duration: 166.118625ms
- prompt eval rate: 800.63 tokens/s
- eval count: 6061 token(s)
- eval duration: 1m20.11340546s
- eval rate: 75.66 tokens/s
Preview the resulting web page here
Note: The result is based on the initial output with no further prompts except a short top snippet to add a link back to this blog post.
Final Thoughts
There is a lot of noise surrounding Google’s AI releases, and many reviewers seem to dislike the “corporate” origin of the model. But as a vibe coder, I don’t care about the corporate narrative. I care about the tool.
Gemma 4 is fast, it is remarkably efficient on moderate hardware, and its ability to handle the intersection of design and logic is unparalleled. In an ocean of LLMs, I’ve found my anchor.
If you’re tired of the benchmarks and just want a model that works, download Gemma 4. If you have previewed the HTML page it made, then you will know if this LLM is a good fit for your needs.